
 2023 애니 강추 작품 !")
")




Nvidia에서 Qwen3.6-27B-FP8의 양자화 모델인 Qwen3.6-27B-NVFP4 모델을 공개했습니다. 파라미터수와 파일 크기는 줄어들었지만 성능은 원 모델 성능과 대등한 결과를 보인다고 합니다. Local Ollama 사용하시는 분들을 위한 성능 비교 앱을 소개합니다. Local Ollama 실행 환경이 모두 다르기에 자신만의 모델별 성능 표를 구성해 보시는 것도 좋을 것 같습니다. 그 외, 토큰 다이어트 관련 소식도 살펴 보십시오.
Qwen3.6-27B-NVFP4 모델 발표
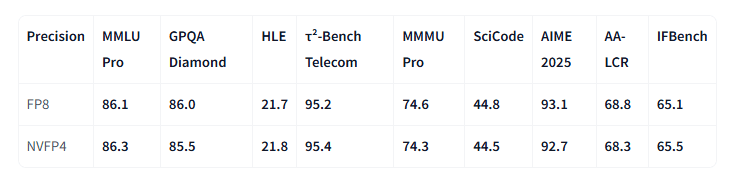
Qwen3.6-27B 원본 모델은 FP8입니다. 6/26이 Nvidia에서 NVFP4 양자화 모델을 Huggingface를 통해서 공개했습니다. 참고로, “NV-” 접두어가 있는 모델은 NVidia CUDA에 맞도록 양자화한 모델로서 NVidia GPU에서 성능을 발휘하는 모델들입니다. Qwen3.6-27B-NVFP4 모델을 보면 파라미터가 28B=>18B, 파일 크기는 30.9GB=> 21.9GB 로 작아졌지만 성능은 원 모델과 대등한 수준을 나타내고 있습니다.
Local LLM matrix, Local에서의 Ollama 모델 성능 비교 앱 Beta
목적: 사용자의 로컬 하드웨어·설정·프롬프트·응답 제한에서 Ollama 모델들이 실제로 어떻게 동작하는지 직접 측정할 수 있게 함
주요 기능:
- 로컬 Ollama 모델 자동 탐지
- 로컬 벤치마크 프로파일 실행
- 시간에 따른 결과 비교(히스토리 보관)
- 선택적 로컬 Judge 리뷰(OlLama 통해)
- 결과 및 히스토리 내보내기: Markdown, HTML, CSV, JSON, ZIP 형식 지원
구현: Python + Streamlit 기반, macOS 우선(현재 가이드/검증은 macOS 중심). Linux/Windows는 수동으로 가능하지만 완전 검증 아님.
공개 베타 상태 및 품질 지표:
- 버전 v0.37.2
- 깔끔한 공개 저장소(초기 커밋 한 건)
- 181개의 자동화 테스트 통과
- 클린룸 설치 리허설 통과
- 대표 모델/프로파일/ Judge 검증 통과
- 로컬 Judge 재시도/폴백 및 빈 응답 케이스 문서화
- GitHub 이슈 템플릿 포함
알려진 한계:
- 베타 단계(완성된 1.0 아님)
- 모든 Ollama 모델 호환 보장 불가
- 큰 모델과 Judge 모델은 느리거나 메모리 부담 큼
- 공개 벤치마크는 참고용일 뿐 로컬 결과와 다를 수 있음
- 현재 설치/가이드는 macOS 우선
Hermes vs OpenClaw 일일 사용해 본 후기
Hermes 대화방 게시글이라서 어쩌면 Hermes에 유리한 결과일 수도 있음을 아시고 읽어 보시기 바랍니다.
======
실험 목적 및 작업 유형
작성자는 Hermes와 OpenClaw를 하루 동안 동일한 프롬프트로 병렬 테스트함.
주된 사용 사례:
- 개인 비서(예약·이메일·리마인더·기억)
- 개발자(창의적 작업: scout→planner→coder→감사)
- 개발 작업 오케스트레이션.
사용한 모델/구성
- Scout: Mimo v2.5
- Planner: Opus
- Planner verifier: GLM-5.2
- Coder: Composer 2.5
- Auditor: GPT-5.5-High
- 오케스트레이션과 개발 워크플로는 Composer 및 Mimo v2.5 Pro 기반.
핵심 비교 결과
- 토큰 효율성: OpenClaw가 동일 작업에서 약 10–20% 적은 토큰을 소비함(더 비용 효율적).
- 스킬 생성/학습: Hermes가 더 많은 스킬을 자동으로 생성·학습함. OpenClaw는 스킬 생성 시 승인이 필요해 제어가 더 쉬움.
- 대화 지속성/품질: OpenClaw: 긴 대화 및 큰 컨텍스트 윈도우에서 더 안정적으로 대화 유지.
- Hermes: 긴 대화에서 응답 품질이 저하되는 경우가 있었으나, 새 대화를 시작하거나 맥락을 빠르게 파악하는 데는 우수.
사용자 경험: Hermes 쪽 데스크톱 앱(특히 커뮤니티에서 개발된 Hermes-One, hermes-ui 등)이 강점으로 꼽힘. OpenClaw은 적절한 데스크톱 GUI가 부족하다고 느낌.
총 토큰 사용량: OpenClaw 약 42M 토큰, Hermes 약 73.5M 토큰. 작성자는 캐시 히트율 등으로 실제 비용 차이는 더 작을 수 있다고 언급(대략 42M vs 53M 추정).
종합 평가
- 전반적 경험 측면에서는 Hermes가 우세(앱, 커뮤니티, 오케스트레이션 능력).
- 비용·토큰 효율을 더 중요시하면 OpenClaw가 매력적일 수 있음.
- OpenClaw는 과거 불안정했으나 최신 버전은 많이 개선됨. 다만 GUI·사용성에서 아쉬움이 있음.
하루 50M 토큰 소비하던 OpenClaw 토큰 절감 방법
문제 상황
- 게시자 환경에서 LLM API 토큰 사용량이 며칠 사이에 급증(6일에 약 196M 토큰, 일부 날은 ~50M 토큰).
- 로그(.jsonl transcripts) 분석 결과 토큰의 약 95%가 cacheRead(과거 대화·세션을 다시 읽음)로 소비됨. 실제 새 작업 비중은 5% 미만.
- 단일 에이전트(“main”)가 전체 사용량의 약 56% 차지. 해당 에이전트는 사용하지 않는데도 하트비트(메시지 검사)를 30분마다 수행하며, 매번 수개월치(약 225k 크기) 세션 기록을 읽고 “HEARTBEAT_OK”만 응답함 → 엄청난 낭비.
원인
- 유휴(또는 폐기된) 에이전트를 하트비트가 계속 깨워 세션 전체를 읽는 구성.
- 개발자가 “비활성화”로 설정해뒀다고 생각한 설정(빈 값 등)이 실제로 작동하지 않아 계속 실행됨.
- 여러 에이전트가 같은(혹은 계속 누적되는) 세션 ID를 재사용해 컨텍스트가 계속 불어남.
해결 방법 (게시자가 실제로 적용한 수단)
- bloated(비대해진) 세션 데이터 삭제 — 하트비트가 매번 불러오는 대규모 이력 제거로 즉시 비용 절감.
재발 방지를 위한 설정 변경:
- heartbeat every: “0m” 으로 완전히 끄기(정말 아무 일도 안 하는 에이전트의 경우).
- 또는 isolatedSession: true + lightContext: true 설정으로 하트비트가 매번 전체 히스토리를 읽지 않고 작은, 가벼운 컨텍스트에서만 실행되게 함(문서상으로는 ~100k 토큰 → ~2–5k 토큰으로 감소).
- 다른 에이전트들도 세션을 리셋해서 각 실행이 깨끗한 상태에서 시작되도록 함.
추가 팁·권고:
- .jsonl 전사 파일을 읽어 각 턴별 토큰 사용량(input/output/cacheRead)을 확인하면 원인 파악이 빠름(추정이 아니라 ‘영수증’ 확인).
- cacheRead 비율이 높으면 “과거 읽기에 비용을 지불하고 있는 것”이므로 우선 점검 대상.
- 하트비트가 실질적 필요가 없다면 끄는 쪽이 안전(대규모 시스템에서 작은 절감도 누적되면 큼).
- “꺼놨다”고 생각되면 실제로 동작 여부를 검증하라(빈 설정이 작동하지 않는 사례 존재).
커뮤니티 반응
- 많은 사용자가 동일 문제 경험 보고(하트비트 관련 토큰 누수).
- 일부는 하트비트 기본값을 끄거나 제거하자는 의견.
- 한 댓글은 NeuralMind(로컬 인덱싱 기반 툴)를 대안으로 제시: 세션 누적이 아예 생기지 않아 토큰 절감 효과 크다고 주장(반박·보안 논쟁도 존재).
많은 사람들이 “cacheRead 체크, 세션 정리, 하트비트 정책 재검토“를 핵심 권장사항으로 보고 있음.
바로 할 수 있는 것
- .jsonl 전사에서 에이전트별/턴별 token usage 확인(특히 cacheRead 비율).
- 비활성 에이전트의 heartbeat를 0m으로 끄거나 isolatedSession+lightContext 적용.
- 대형 세션(오래된 대화) 삭제 후 하트비트 동작 확인.
- 동일 세션 ID를 재사용하는 작업 흐름이면 각 작업마다 세션 초기화하도록 수정.
llama-server 셀프 호스팅에서 매 번 프롬프트 캐시 다시 읽기 방지하기
상황 및 환경
- 모델: Qwen3.6-27B-Q8_0, 듀얼 RTX 3090(텐서 병렬)
- 서버: llama-server에 –cache-prompt, –ctx-size 400000, –parallel 2
- 클라이언트: OpenClaw(랜 연결)
- 문제는 세션 토큰이 ~90k를 넘기면서 발생
증상
- 매 턴마다 llama-server 로그에 “forcing full prompt re-processing due to lack of cache data” 및 “erased invalidated context checkpoint” 반복 출력
- 매 응답마다 약 91k 토큰을 처음부터 재처리
→ 프롬프트 평가 130초(약 2분) 소요 → 장기 세션에서 응답이 매우 느림
원인
- OpenClaw 기본 설정 contextInjection이 “always”로 되어 있어, 매 턴(연속 응답 포함)마다 AGENTS.md 등 부트스트랩 파일(약 15KB)을 시스템 프롬프트에 재주입
- 프롬프트 접두사가 조금이라도 변하면 llama.cpp의 캐시가 일치하지 않아 재처리하게 됨 → 캐시가 ‘깨진’ 것이 아니라 클라이언트가 프롬프트를 매번 달라지게 함
해결(핵심)
- OpenClaw 설정 변경:
openclaw config set agents.defaults.contextInjection continuation-skip --merge
- 게이트웨이 재시작: 새 사용자 메시지일 때만 부트스트랩 파일 주입, 연속(turn)에서는 건너뜀 → 캐시 재사용 가능
결과(개선 효과)
- 재처리 토큰: 91,403 → 약 513 신규 토큰(실제 변경분만)
- 프롬프트 평가 시간: 130초 → 1.3초
- 캐시 재사용률: 0% → 99.7%
- 응답 속도: 2분+ → 약 5초 (약 100배 개선)
추가로 조정한 항목(권장 사항)
- –ctx-size 320k → 400k (세션당 컨텍스트 토큰 상향)
- OpenClaw contextTokens를 200k로 맞춤
- memoryFlush.softThresholdTokens를 30k → 10k로 낮춤
진단 방법
llama-server 로그에서 아래 메시지 확인:
- 문제: “forcing full prompt re-processing due to lack of cache data”, “erased invalidated context checkpoint”, 프롬프트 처리 시간이 길음
- 정상: “restored context checkpoint”, f_keep ≥ 0.99, “graphs reused =”, 처리 시간 짧음
핵심 교훈
- 로컬 llama.cpp 기반 환경에서는 클라이언트의 프롬프트 주입 방식이 캐시 재사용에 결정적 영향.
- OpenClaw의 contextInjection 기본값이 로컬 캐시 환경과 맞지 않아 성능이 크게 저하될 수 있음.
※ 지난 게시글:
- AI 뉴스 훑어보기 – 2026.6.24
- AI 뉴스 훑어보기 – 2026.6.19
- AI 뉴스 훑어보기 – 2026.6.18
- AI 뉴스 훑어보기 – 2026.6.17
- AI 뉴스 훑어보기 – 2026.6.16
※ 출처: r/LocalLLM, r/openclaw, r/unsloth, r/opencode, r/claude

 prometheus + grafana 설정")




