
 2023 애니 강추 작품 !")
")




Gemma4+Ollama+Obsidian이용한 자신만의 로컬 지식 저장소 구축 방법, Unsloth로 Gemma4-12B-QAT 훈련한 모델에서 도구 호출이 안되는 문제, QAT 성능이 좋지 않을 수도 있다는 시험 결과, 3090에서 Qwen3.6-27B 성능을 2배 이상 올린 후기가 있습니다.
Gemma 4 + Ollama + Obsidian, 무료로 Local 2nd Brain 구축하기
Obsidian에 저장한 개인 노트(바이오트)를 로컬에서 실행되는 LLM으로 검색·요약·연결해 ‘로컬 2nd brain’을 만드는 방법으로 클라우드나 외부 서버로 데이터가 나가지 않음(프라이버시 강조).
스택 구성: Obsidian(노트 보관) + Ollama(로컬 LLM 호스팅, OpenAI 호환 API) + Gemma 4(로컬 모델) + Obsidian용 copilot/검색 플러그인(예: Smart Connections, Copilot for Obsidian 등).
왜 Gemma 4 인가?
- Apache 2.0으로 공개·상용 사용 허가.
- 멀티모달(이미지 인식 가능)
- 매우 큰 컨텍스트 윈도우(모델 변형에 따라 128K–256K 지원)
- 소비자 하드웨어에서 구동 가능한 여러 변형 존재(E4B 약 9.6GB 등).
핵심 설치·설정 단계 (요약)
- Ollama 설치: (페이지에 제시된 패키지/스크립트 명령으로 설치)
- Gemma 4 풀(Pull): 예) ollama pull gemma4 (하드웨어에 맞는 변형 선택 가능: 12B, 26B 등)
- 컨텍스트 윈도우 수정(중요): Ollama가 기본으로 모델을 작은 컨텍스트로 설정해 두므로 직접 modelfile을 만들어 num_ctx 값을 크게 올릴 것(예: 32768).
- 예시:
- gemma4-brain.modelfile 내용 예시:
FROM gemma4 PARAMETER num_ctx 32768
- ollama create gemma4-brain -f gemma4-brain.modelfile 처럼 생성
- gemma4-brain.modelfile 내용 예시:
- 예시:
Obsidian + 플러그인 설치: Obsidian 설치 후 community plugin(예: Smart Connections 또는 Copilot for Obsidian)을 설치하고, 플러그인에서 제공자(provider)를 Ollama로 설정하여 로컬 모델과 연결(플러그인 설정에서 모델 선택).
임베딩 인덱싱: 플러그인이 바탕으로 노트들을 임베딩해 검색 인덱스를 구축(초기 인덱싱은 10–30분, 노트 수에 따라 다름).
사용: 플러그인 채팅 인터페이스로 질문하면 관련 노트를 검색해 근거 기반 답변(요약·비교·연결 등)을 제공.
잘 작동하는 것
- 오래된 노트 찾아내기, 여러 노트 간 교차 요약·비교, 연구 노트 종합, 저널 회고 등에서 높은 효용.
- 완전 오프라인 사용 가능(프라이버시 유지).
제한점·단점
- 대규모 바이얼트(2,000+ 노트)에서는 검색/리트리벌 전략(청킹, 임베딩 품질 등)에 따라 성능 저하. 복잡한 다문서 추론은 컨텍스트 한계에 걸릴 수 있음.
- 로컬 추론은 클라우드보다 응답 속도 느림(수 초 수준).
- 플러그인에 따라 이미지 전달/멀티모달 지원 미흡할 수 있음.
권장 하드웨어
- 최소(작동): 랩탑 16GB RAM(M1/M2/M3/M4 등) — 느리지만 작동.
- 잘 작동: 24–48GB RAM 혹은 16–24GB VRAM GPU.
- 최상: 24GB+ VRAM 장비에서 큰 변형(26B/31B) 사용 가능.
비용
- Obsidian 개인용 무료, Ollama 및 Gemma 4 자체는 무료(오픈 소스/라이선스 허용).
- 주요 비용은 컴퓨팅 전력(전기)과 장비(이미 보유한 경우 추가 없음).
Ollama 0.24 to 0.30.6 업그레이드 후, gpt-oss:20b 성능 하향 발생 원인 추론
Ollama 0.24 + NVidia A100+gpt-oss:20b 성능이 ~144 TPS 정도였는데 Ollama 0.30.6으로 업그레이드하고 나서는 ~109 TPS 수준으로 줄어 들었다고 합니다. 이의 추정 원인은 다음과 같다고 제시하고 있습니다.
- Ollama가 해당 버전들 사이에서 llama.cpp 백엔드를 여러 번 변경했습니다. 대략 0.28 즈음에 기본 llama.cpp를 대대적으로 업데이트해서 기본 스케줄링 및 배칭 동작이 바뀌었습니다. OLLAMA_NUM_PARALLEL 및 OLLAMA_MAX_LOADED_MODELS 환경 변수를 0.24 설정과 맞추어 설정해 보세요.
2. vGPU 프로파일도 요인이 될 수 있습니다 — CUDA 13.0의 A100D-7-80C는 비교적 새로운 드라이버 스택입니다. Ollama 0.30.x는 다른 CUDA 커널 컴파일 경로를 사용하고 있을 수 있습니다. OLLAMA_CUDA_FORCE_CC(귀하의 A100 연산 능력인 8.0으로 설정)를 적용하면 차이가 나는지 확인해 보세요.
3. 모델 양자화 처리 방식이 변경되었습니다. 0.24는 KV 캐시 양자화 기본값에 대해 더 관대했습니다. API 호출에 “num_ctx”: 4096을 명시적으로 추가해 보면 성능 차이가 줄어드는지 확인할 수 있습니다.
vGPU로 분할된 A100에서 20B 모델이 144 TPS를 기록하는 것은 이미 준수한 성능입니다. 다운그레이드로 성능이 복구된다는 점은 하드웨어 문제일 가능성이 낮고, Ollama의 새로운 서버 파이프라인 어딘가에서 지연이 생기고 있을 가능성이 큽니다.
1개의 3090에서 Qwen 3.6-27B 2배 성능: Ollama 35.7 TPS에서 llama.cpp+MTP 80.2 TPS로의 단계별 시험
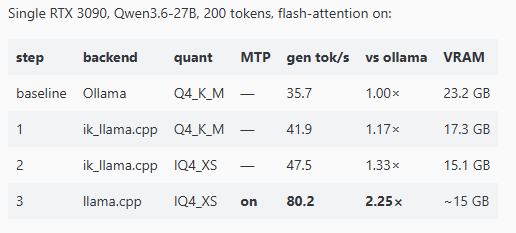
- 실험 개요: 단일 RTX 3090에서 Qwen3.6-27B(200 토큰, flash-attention 활성화)로 성능을 단계별로 측정.
- 핵심 결과: Ollama 기본(Q4_K_M)에서 35.7 tok/s → llama.cpp + MTP(IQ4_XS)에서 80.2 tok/s로 약 2.25× 향상.
엔진·양자화(ik_llama/llama.cpp)만으로도 35.7 → 47.5 tok/s(≈1.33×) 증가. - MTP(다중 토큰 예측, speculative decoding)만으로는 45.1 → 80.2 tok/s(≈1.78×)의 추가 향상. 최종 2.25×는 엔진+양자화+MTP의 누적 효과.
- MTP 방식은 초안(draft)을 병렬로 생성하고 메인 모델이 검증하므로 품질 저하 없이 처리량 향상(무손실).
튜닝·설정 팁:
최적 지점: –spec-draft-n-max 3(=n-max 3)에서 최고(80.2). n-max 4는 떨어짐.- p-min(수용 임계값)을 너무 높이면(예: 0.6) 수락률은 올라가지만 전체 토크/초는 감소(예: 54 tok/s). 작업 특성에 따라 p-min을 낮게 두는 편이 좋음(코드 등 예측 가능한 작업은 유리).
- f16 KV가 q8 KV보다 더 나음(본 실험에서).
실험·환경 관련 주의사항:
Ollama의 GGUF 변환이 Qwen3.6의 변경(rope 요소 수)과 맞지 않아 bartowski의 변환 GGUF 사용.- ik_llama에서 MTP 플래그가 초기에는 레거시로 거부되었으나, 댓글에서 canonical 형태(–spec-type mtp:n_max=…,p_min=…)로 동작함. (따라서 ik_llama에서도 MTP 사용 가능)
- 결과는 단일 GPU·단일 요청 환경의 숫자이며, prefill(프롬프트 처리)은 짧은 프롬프트로 노이즈가 있으므로 본문 수치는 “생성(디코드) 성능” 중심임.
- 긴 컨텍스트(>64k)에서는 prefill(프롬프트 평가) 시간이 병목이 될 수 있어 MTP의 이득이 상대적으로 작아짐.
품질 영향: 동일한 변환에서 Q4_K_M vs IQ4_XS 퍼플렉시티 차이는 무시할 수준(예: Δ ≈ +0.0007), 이 모델에서는 품질 손실 거의 없음.
추가 정보: 작성자는 Ollama를 일상용으로 유지하되, “토큰/초” 최대화 목적이면 llama.cpp/llama-server 기반 구성이 더 빠르다고 평가.
Gemma4-12B-QAT 도구 호출 실패는 Bug?
6월 6일 발표한 Google의 Gemma4-12B-QAT를 Unsloth로 Fine-tuning한 모델에서 도구 호출이 실패한다고 합니다. Google 원본 모델에서도 동일한 현상이 발생하는 것인지 작성자가 이용한 Unsloth 훈련 과정에서의 문제인지는 모르는 상태입니다.
===
- 작성자 Unsloth로 학습·내보낸 Gemma 4 12B QAT 모델에서 “tool calling” 기능이 완전히 깨진 현상을 보고함.
- 비‑QAT 버전에서는 이러한 오류가 발생하지 않음(문제가 QAT 변형과 연관돼 보임).
W load: control-looking token: 50 '<|tool_response>' was not control-type; this is probably a bug in the model. its type will be overridden W load: control-looking token: 212 '</s>' was not control-type; this is probably a bug in the model. its type will be overridden
원인 추정 및 문제 영향
- 문제 설명: ‘<|tool_response>’ 같은 툴 관련 토큰들이 GGUF 사전에 일반 텍스트 토큰으로 들어가고, llama.cpp가 시작 시 강제로 토큰 타입을 덮어써서 모델의 내부(생각) 영역과 툴 호출 경계가 흐려짐 → 함수 호출(툴 콜)이 일관되지 않음.
- 작성자는 기존 GGUF 파일의 메타데이터를 수동으로 패치해서 토큰 타입을 수정할 수 있는지, 아니면 원본 safetensors에서 토큰 정의를 명시적으로 넣어 다시 내보내야 하는지 묻고 있음.
0.00.074.191 I - CUDA0 : NVIDIA GeForce RTX 4080 SUPER (16375 MiB, 15061 MiB free) 0.00.074.205 I - CPU : 12th Gen Intel(R) Core(TM) i7-12700KF (98097 MiB, 86472 MiB free) 0.00.074.254 I system_info: n_threads = 12 (n_threads_batch = 12) / 20 | CUDA : ARCHS = 890 | USE_GRAPHS = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 | 0.00.074.293 I srv init: using 19 threads for HTTP server 0.00.080.574 I srv load_model: loading model 'E:\models\gemma-4-12B-it-qat-UD-Q4_K_XL.gguf' 0.01.205.117 W load: control-looking token: 50 '<|tool_response>' was not control-type; this is probably a bug in the model. its type will be overridden 0.01.205.496 W load: control-looking token: 212 '</s>' was not control-type; this is probably a bug in the model. its type will be overridden 0.01.242.092 W load: special_eog_ids contains '<|tool_response|>', removing '</s>' token from EOG list 0.03.279.202 W llama_context: n_ctx_seq (32768) < n_ctx_train (262144) -- the full capacity of the model will not be utilized 0.03.370.810 I slot load_model: id 0 | task -1 | new slot, n_ctx = 32768 0.03.370.887 I srv load_model: prompt cache is enabled, size limit: 8192 MiB 4.07.196.023 I srv params_from_: Chat format: peg-gemma4
보다 많은 Gemma4와 Qwen3.6 모델 비교 결과
실험 목적: 서로 다른 Gemma4 및 Qwen3.6 모델/양자화(quantization) 버전들이 큰 정수 덧셈 문제(예: 998604052310776342 + 249349834805792420)에 대해 정답(숫자 하나만)을 얼마나 잘 출력하는지 평가.
실험 조건: 각 모델에 대해 1000번씩 질의, 기본은 temperature=0, enable_thinking=False(생각 모드 비활성), 응답 스트리밍 및 답을 정수로 파싱하는 방식 사용.
핵심 결과(모델별 정답률 표본):
- Qwen3.6-27B-Q4_K_S (MTP): 95.5% (가장 높음)
- Qwen3.6-35B-A3B-UD-Q4_K_S: 87.4% (temp=0), 86.5% (temp=1)
- Gemma-4-31B-it-Q4_K_S: 83.8%
- Gemma-4-26B variants: 성능 편차 큼 (예: 일부 QAT는 약 51% 수준, Q8_0 ~73%)
- Gemma-4-12B: ~31% (temp=1에서는 28.9%)
- 매우 작은/경량화된 Gemma 모델들(E4B, E2B 등)은 거의 실패(0.1% ~ 1.4%)
해석 및 논의:
- QAT(양자화-aware training) 버전들이 이 산술 테스트에서는 기대보다 못한 성능을 보임(특히 일부 QAT가 성능 저하).
- 서로 다른 모델 간 직접 비교 시 주의 필요 — 학습 데이터·토크나이저·아키텍처 차이(예: 일부 모델이 합성 산술 데이터로 더 많이 학습됐을 가능성) 때문에 양자화 영향만으로 단순 비교 불가.
- enable_thinking을 끈 이유: 양자화로 인한 ‘기억 상실’ 효과를 분리하려는 의도와 테스트 속도 이유. 다만 thinking(생각) 모드를 켜면 산술 성능이 더 좋아질 수 있음.
※ 지난 게시글:
- AI 뉴스 훑어보기 – 2026.7.16
- AI 뉴스 훑어보기 – 2026.7.15
- AI 뉴스 훑어보기 – 2026.7.13
- AI 뉴스 훑어보기 – 2026.7.10
- AI 뉴스 훑어보기 – 2026.7.9
※ 출처: r/LocalLLM, r/openclaw, r/unsloth, r/opencode, r/claude





