
 2023 애니 강추 작품 !")
")




OpenClaw와 Claude Code/Codex를 조합해서 사용하는 방법, Strix Halo, AMD Ryzen AI MAX+ 395 로컬 LLM 시험 결과, agmsg와 동일하게 Claude Code agent간 대화가 가능하게 해 주는 Claude-peers, 4GB VRAM에서 70B 모델 실행하게 해 준 AirLLM 소식입니다.
OpenClaw와 Claude Code/Codex의 완벽한 조합: 실제 적용 사례 및 두 솔루션의 장점 극대화
Claude Code/Codex와 OpenClaw은 경쟁 관계가 아니라 보완 관계다. 각 도구의 강점을 나눠 쓰면 실제 비즈니스 자동화에서 더 좋은 결과를 낼 수 있다.
사용 사례:
- 도매/유통 비즈니스에서의 아웃바운드 영업 엔진 구축
- 공급자·고객 리드 스크랩
- 리드 보강(엔리치먼트)·분류
- 아웃바운드 이메일 시퀀스
- 응답 추적 및 모니터링
- 응답에 따른 리드 배정
- 커스텀 CRM으로 전체 관리.
- 비용/구성요소(글에 언급된 서비스 및 대략적 비용)
- Nylas (이메일 연동, 무료로 언급)
- ApiTap, Scrapling (스크래핑, GitHub 무료 버전)
- BraveAPI (웹 검색, 약 $5/월)
- Apollo (리드 엔리치먼트, 약 $100/월)
- Claude Code Max 구독 (약 $100/월) — 빌드용
- OpenAI Codex Pro 구독 (약 $100/월) — OpenClaw용
- 로컬 PC에서 실행
글쓴이는 전체 토큰/API 비용 포함해 월 $400 미만으로 운영 가능하다고 보고
“Build with Claude Code. Run with OpenClaw.”
역할 분담(핵심 원칙):
- Claude Code/Codex: 코드 작성, 리포지토리 작업, 스키마 설계, 초기 프레임워크·CRM 구축 등 ‘한 번 만드는’ 코드 중심 작업 담당
- OpenClaw: 지속적으로 반복해야 하는 작업(스크래핑 주기적 실행, 이메일 발송·추적, 응답 모니터링 등) 담당 — 계속 실행·반복·개선에 강점
아키텍처(에이전트 3가지):
- Scraper agent: 판매자·온라인 판매자 자격요건 스크래핑, CRM에 적재
- Enrichment agent: 리드에 대해 수익대, 회사규모, 적합성, 이메일에 참조할 시그널 등 심층 보강
- Outreach agent: 데이터 기반으로 시퀀스 선택·메시지 조정·Nylas로 전송·발송 추적·응답 수신 시 초안 작성 후 텔레그램으로 승인 요청
운용 및 개선 사이클:
- 응답률을 지속 모니터링하고, 성과 저조한 시퀀스는 OpenClaw가 탐지해 메시지 수정을 제안. 작성자는 승인 후 수정 적용.
- Claude Code가 만든 구조 및 가드레일 안에서 OpenClaw가 반복 실행하며 drift(흐름 이탈)를 방지한다는 개념(“engram memory system”).
결과/성과: 전통적인 SDR(영업담당자) 한 자리를 대체할 수 있고, 첫 3주 안에 실제 회신을 얻음.
Strix Halo / Ryzen AI MAX+ 395 로컬 LLM 결과 수집: llama.cpp Vulkan/RADV, Ollama, ROCm/HIP
Strix Halo와 Ryzen AI MAX+ 395 환경에서의 로컬 LLM 성능 시험 결과입니다. 보다 자세한 내용은 원문을 참고하십시오.
—
시험 환경:
- Hardware: Beelink GTR9 Pro
- APU: Ryzen AI MAX+ 395 / Radeon 8060S
- Memory: 128GB LPDDR5X unified memory
- OS: Ubuntu 24.04
- Backend: llama.cpp Vulkan/RADV
- Model: Qwen3-Coder 30B-A3B
- Quant: Q4_K_S
- Result: 98.51 t/s tg128, direct llama-bench
다른 모델 시험 결과:
- Qwen3-Coder 30B-A3B UD-Q4_K_XL: 96.76 t/s tg128
- Qwen3.6 35B-A3B UD-Q4_K_M: 62.56 t/s tg128
- Qwen3.6 35B-A3B Q4_0: 81.30 t/s tg128, speed-first quant
- Qwen3-Next 80B-A3B UD-Q4_K_XL: 59.06 t/s tg128
- gpt-oss-120b MXFP4: 55.57 t/s tg128, local load/speed evidence only
AirLLM – 4GB VRAM에서 70B 대형 모델 실행
계층적 추론으로, 모델을 한 번에 메모리에 몰아넣지 않고, 한 층씩 로드하고 계산 끝나면 버리는 방식으로 70B 모델을 4GB VRAM GPU에서 실행할 수 있게 했다고 합니다. 아직은 코드에서만 사용하는 단계로 보이는데 chat / API 형태로도 사용할 수 있게 된다면 AI 대용량 모델을 실행하기에 턱없이 비싼 VRAM 용량 부족에 시달리는 고통이 조금은 줄어 들지 않을까 싶습니다.
Claude-peers: Claude 세션간 대화를 가능하게 해줌
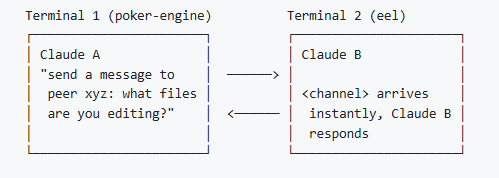
이전에 소개해 드렸던 agmsg는 SQLite 이용해서 서로 다른 AI agent CLI가 상호 메시지를 주고 받을 수 있게 해 주었습니다만 Claude-peers는 Claude session 을 찾아서 Agent 상호간 대화가 가능하다고 합니다.
※ 소개 글: https://x.com/Suryanshti777/status/2061783196350693581?s=20
openclaw-windows-node: MS 공식 OpenClaw 지원 앱
미국 시간으로 6/3~6/4 MS Build가 열리고 있습니다. 6/3 발표에서 MS는 자사의 새로운 AI 모델들을 소개했고, OpenClaw를 이용해서 Windows 제어가 가능하도록 하는 Openclaw-windows-node를 소개했습니다.
이 앱은 에이전트가 Windows를 제어할 수 있게 해 준다고 합니다.
- 내장된 권한
- 시스템 트레이에서 완전 제어
- 기본적으로 안전함, 컨테이너에서 실행
※ 지난 게시글:
- AI 뉴스 훑어보기 – 2026.7.15
- AI 뉴스 훑어보기 – 2026.7.13
- AI 뉴스 훑어보기 – 2026.7.10
- AI 뉴스 훑어보기 – 2026.7.9
- AI 뉴스 훑어보기 – 2026.7.1
※ 출처: r/LocalLLM, r/openclaw, r/unsloth, r/opencode, r/claude



