
 2023 애니 강추 작품 !")
")




Local LLM 구성하실 때 참고하실 실리콘 MAC 관련 벤치마크 정보와 네이티브 MTP 추론 엔진 MTPLX, Ollama Cloud 모델별 응답 성능을 보여 주는 대시보드 사이트 정보가 올라왔습니다.
Anibis OSS: 실리콘 MAC 칩10종 LLM 벤치마크

실리콘 MAC에서 실제로 실행하고 측정한 LLM 성능 비교 분석입니다. 커뮤니티 사용자들의 벤치 결과를 취합하고 분석했기에 실 사용 LLM 모델들과 실리콘 CPU 장착 MAC 모델 성능을 확인할 수 있습니다. Local LLM 구축할 때 가장 많이 하는 질문이 하드웨어 사양 정보인데 통합 RAM을 지원하는 MAC 모델별 성능을 가늠할 정보가 부족한 것도 사실입니다. 이 분석 결과에 따르면 최신 CPU가 아닌 M4 칩이 가성비가 좋아 보입니다. MAC 이용해서 Local LLM 구축하실 분들은 참고하십시오.
MTPLX – 실리콘 MAC을 위한 네이티브 MTP 추론 엔진 (2.24x tps 빠름)
TL;DR
MTPLX는 Apple Silicon(M5 Max 등)에서 MTP 헤드를 이용해 토큰 처리 속도(TPS)를 최대 약 2.24× 향상시킴.
예시: Qwen 3.6 27B(4-bit MLX)에서 28 tok/s → 63 tok/s(온도 0.6, top_p 0.95, top_k 20) — 단, 이 수치는 160토큰 고-수용도 프롬프트 기준이며 실사용에서는 보통 50–55 TPS 예상.
- 모든 MTP 모델에서 작동: 외부 드래프터 불필요. 추가 메모리 사용 없음. 모델 자체의 내장 MTP 헤드 사용. 해당 헤드를 탑재한 모든 모델에서 작동합니다.
- 비탐욕적: 유사한 추측적 디코딩 프로젝트와 달리, 우리는 거부 샘플링을 이용한 수학적으로 정확한 Temperature Sampling을 사용합니다. 모든 작업에 대해 조정 가능한 Temperature. Apple Silicon에서의 다른 모든 추측적 디코딩 프로젝트는 탐욕적(그리디) 전용입니다.
- 커스텀 커널: 커스텀 Metal 커널, 컴파일된 검증 그래프, 혁신-테이프 GDN 롤백, 드래프트 전용 재양자화된 LM 헤드를 포함한 패치된 MLX 포크 기반.
- 전체 CLI: mtplx start 위자드, 모델 다운로드, 4단계 MTP 호환성 감지 기능을 갖춘 모델 검사, 구성 가능한 깊이 2-7+, OpenAI/Anthropic API 서버, 브라우저 채팅, 터미널 채팅, 벤치마킹 스위트, 헬스 진단, 충돌 안전 팬 제어 및 유휴 인식 자동 복원, 그리고 562개 테스트 스위트.
- 전체 서빙 스택: OpenAI + Anthropic 호환 API, 브라우저 채팅 UI, 터미널 채팅. 에디터를 localhost로 향하게 하고 바로 사용하세요.
무엇인가
- MTPLX는 모델에 내장된 MTP(multitoken prediction) 헤드를 ‘draft(시안) 생성기’로 사용해 speculative decoding을 수행.
- 외부 drafter(추가 모델)를 쓰지 않아 메모리 부담이 없음.
- 다른 speculative 기법과 달리 온도(temperature)를 유지하는 정확한 확률비(rejection sampling)를 사용 — 그 결과 비탐욕적(non-greedy) 샘플링 가능.
아키텍처·기술적 혁신
- patched MLX(MLX 런타임 포크) + 커스텀 Metal 커널로 구현.
- 주요 커널/시스템:
- innovation-tape GDN 캡처: 드래프트 중의 작은 상태 델타만 기록해 롤백/복구 처리(메모리 절약).
- GraphBank: verify용 컴파일된 그래프 캐시(다양한 suffix_length/depth/profile 별로 재사용).
- draft-only requantised LM head: 드래프트 전용 4-bit lm_head로 드래프트 속도 향상.
- 소형 verify qmv: MTP에 맞춘 verify 셰이프 최적화.
전체 스택: CLI(설정/벤치/진단 등), OpenAI·Anthropic 호환 API 서버, 브라우저 UI 및 터미널 채팅 제공.
작동 방식(핫 루프)
한 사이클: MTP 헤드가 K 토큰을 순차적으로 드래프트 → 대상 모델이 한 번에 K 토큰을 verify → 확률비(Leviathan-Chen) 기반으로 각 위치 accept/reject → 거부된 위치에 대해 residual correction으로 깨끗한 대체 생성 → 인정된 토큰의 GDN 상태 델타는 innovation-tape에 커밋.
해결한 주요 문제들 및 대응
- 재귀적 깊이에서의 정확도 붕괴: MLX가 speculative 사이클마다 MTP attention KV 캐시를 초기화하는 문제를 수정하여 수용률 대폭 개선.
- 정밀도(precision) 불일치:BF16 MTP 헤드와 4-bit trunk의 불일치로 양자화 노이즈가 증폭됨. INT4로 보정된 MTP 가중치로 재현성 개선.
- MLX의 verify 병목:verify 패스와 MLP 오버헤드 최적화(메탈 셰이더 패치 등)로 verify 시간 대폭 단축.
- TPS 감소(장시간 생성 시): 장시간 루프에서 GPU 부하로 SoC 온도가 올라가며 성능 저하 발생. MAX(fan full) 모드와 ThermalForge 기반 팬 제어로 온도·클럭 유지 문제 해결.
제한사항·주의점
- 제시된 최고 TPS는 프롬프트/하드웨어/샘플링 설정에 따라 달라짐(실사용에서는 평균적으로 낮음).
- 긴 응답(8k+ 토큰)에서는 팬 제어 없이는 TPS가 떨어질 수 있음.
- 많은 MLX 양자화 모델들이 MTP 헤드를 제거했기 때문에 현재 호환되지 않는 모델이 많음 — MTP 헤드를 보존한 MLX 양자화 모델이 필요.
- 저자는 Qwen 3.6 27B용 MTPLX 최적화 체크포인트와 GitHub 저장소(공개 리포지토리), HuggingFace 배포를 제공한다고 밝힘.
nimbalyst – Visual Workspace Editor
현재 지원 모델: Codex 및 Claude Code 지원. Opencode와 Copilot은 알파 상태.
주요 기능:
- 에이전트가 사용자가 편집하는 동일 파일을 시각적 에디터에서 편집.
- 블록 단위 수락/거부가 가능한 빨간/초록(diff) 변경 표시.
- 세션, 파일, 작업이 상호 연결되어 작업 추적 가능.
- 병렬 세션을 터미널 탭 대신 칸반 보드로 관리.
- 작업(tasks)이 에이전트 워크스페이스 안에 존재하여 계획·버그·작업이 세션·파일과 연계.
- 개발자 워크플로우 기능: worktrees, workstreams, 시각적 Git 관리, 에이전트의 Git 제안 기능 등.
세부 정책·구성:
- 로컬 퍼스트: 파일은 사용자의 파일시스템에 공개 포맷으로 보관.
- 라이선스: 데스크탑 및 iOS 앱은 MIT, 협업 서버는 AGPL.
- 확장 시스템 존재(커스텀 에디터·도구 추가 가능).
Caveman Review: 토큰 소비 65% 절감 Skill
- 설치 편의성: 1줄 설치 스크립트가 여러 로컬 에이전트(예: ollama, vllm, aider)를 자동 감지해 설정을 간편하게 해 줌.
- 토큰 절감 효과:
- 프로젝트 측 벤치마크에서 최대 65% 절감 주장.
- 작성자의 로컬 테스트(예: ollama 7B)에서는 응답 길이가 대폭 줄어 70토큰 → 약 15토큰 수준으로 감소한 사례 보고.
- 다른 환경(llama.cpp 등)에서는 30–40% 절감이 더 현실적이라는 관측.
- claude.md(컨텍스트 문서) 파일을 약 40% 줄여주는 companion 툴(caveman-compress)이 장기적으로 더 큰 이득일 수 있음.
한계와 주의점:
- 극단적(ultra) 모드는 문서 포맷을 깨뜨리거나 중요한 맥락을 누락할 위험이 있음.
- 단순히 “be brief” 같은 지시로도 대부분 효과를 낼 수 있음(의도 보존 측면에서 유리).
[단신] vLLM에 Qwen 3.5+ 모델용 TurboQuant Fix 합병됨
기존에 ‘Not Implemented’ 오류 발생했으나 이를 수정한 버전이 vLLM 메인 소스에 병합되었다고 합니다.
--kv-cache-dtype turboquant_4bit_nc
옵션 사용하면 된다고 하고, 이 외의 다른 양자화 옵션도 선택 가능하다고 합니다. Qwen 3.5:27B 모델 시험에 성공했다고 하는데 Release 에 보면 아직 정식 Package에는 포함되지 않은 것으로 보입니다.
Par Llama – Ollama와 다중 제공자 Chat을 위한 TUI
소개
Parllama는 터미널 기반 TUI 애플리케이션으로, 처음에는 Ollama 모델 관리를 위해 시작됐고 이후 멀티-프로바이더 LLM 채팅 클라이언트로 발전한 도구로 작성자(probello)가 거의 2년간 매일 사용하며 안정화했다고 설명.
Ollama(로컬) 관련 핵심 기능
- 모델 Pull, Delete, Copy, Create(진행률 표시) 등 모델 관리 기능.
- Create 인터페이스에서 네이티브 모델 양자화 지원.
- Ollama 모델 라이브러리 브라우징, 사이즈/이름별 정렬.
- 모델 상세 보기(파라미터 정보), 실행 중인 모델 모니터링(ps 폴링).
채팅 인터페이스 기능
- 스트리밍 채팅(비전 모델 포함).
- 탭 방식의 다중 세션(여러 대화).
- 어시스턴트 메시지 생성 중 편집·계속 생성 기능.
- 커스텀 시스템 프롬프트 및 Fabric 패턴 임포트.
- 세션 간 지속 메모리, 대화 Markdown 내보내기.
- 템플릿 실행 — 응답 내 코드 스니펫을 Ctrl+R로 실행.
클라우드/다중 프로바이더 지원
- OpenAI, Anthropic, Groq, XAI, OpenRouter, Deepseek, Gemini, Mistral 등 여러 클라우드 프로바이더 통합.
- 프로바이더별 모델 캐싱(로컬 Ollama: 168시간, 클라우드: 24–48시간).
- 사용하지 않는 프로바이더 비활성화 옵션(타임아웃 방지).
기술 스택 및 플랫폼
- Python + Textual + Rich로 작성.
- 크로스플랫폼: macOS, Linux, Windows, WSL.
- 설치 예시 커맨드가 언급됨: uv tool install parllama
10일 걸려 만든 AI Powerhouse (Ollama + Gemma 4 + Claude Cowork 3P + Browserless)
목적 및 성과
- 작성자는 10일 만에 비용을 크게 들이지 않고 로컬에서 동작하는 AI 개발 환경을 구축했다고 보고함.
- 결과물은 로컬 LLM(Ollama + Gemma 4 등)과 Claude Cowork 3P 인터페이스, 그리고 브라우저 상호작용을 위한 browserless 컨테이너를 결합한 시스템으로, 유료 브라우저 확장이나 API 구독 없이 웹을 탐색·분석·자동화할 수 있음.
사용된 주요 구성 요소(스택)
- 기초: Visual Studio Code(주 IDE), Ollama(로컬 모델 실행), Gemma 4(31B, 클라우드 혼합 사용)
- 인터페이스: Claude Cowork(3P, 개발자 모드로 사용, 스킬 수동 로드 필요)
- 네트워킹: Tailscale로 Ollama 인스턴스와 Claude Cowork 연결
- 웹 상호작용(브라우저 우회):
- Docker Desktop 설치
- Browserless 컨테이너를 통해 WebSocket(ws://localhost:3000)으로 AI가 헤드리스 브라우저에 접근
- GEO(Generative Engine Optimization) 스킬 파일을 Cowork에 로드해 Browserless와 연동
실행 예시 및 명령
- 작성자가 자주 언급한 실행 명령: ollama launch claude –model gemma4:31b-cloud
- Gemma4는 일부는 로컬에서 Ollama로, 일부는 31B 클라우드로 운용(완전 로컬이 아님).
하드웨어·성능 관련
- 작성자 랩탑: LG Gram, Intel Core Ultra 7, RAM 32GB. 전체 스택 구동 시 약 25GB 메모리 사용 보고.
- Gemma4 31B 클라우드가 현재 환경에서 가장 안정적이라고 평가. 일부는 Gemini 3 flash가 더 빠르다고 언급.
부가 정보·주의
- Claude Cowork 3P는 자유롭게 쓸 수 있으나 스킬을 수동으로 로드하는 등의 설정 난이도가 있음.
- 시스템 리소스(특히 메모리)를 주의해야 함.
- 작성자는 GitHub 등에서 GEO 스킬 파일을 구해 사용했다고 하나 내부 동작 원리를 완전히 이해하진 못한다고 밝힘.
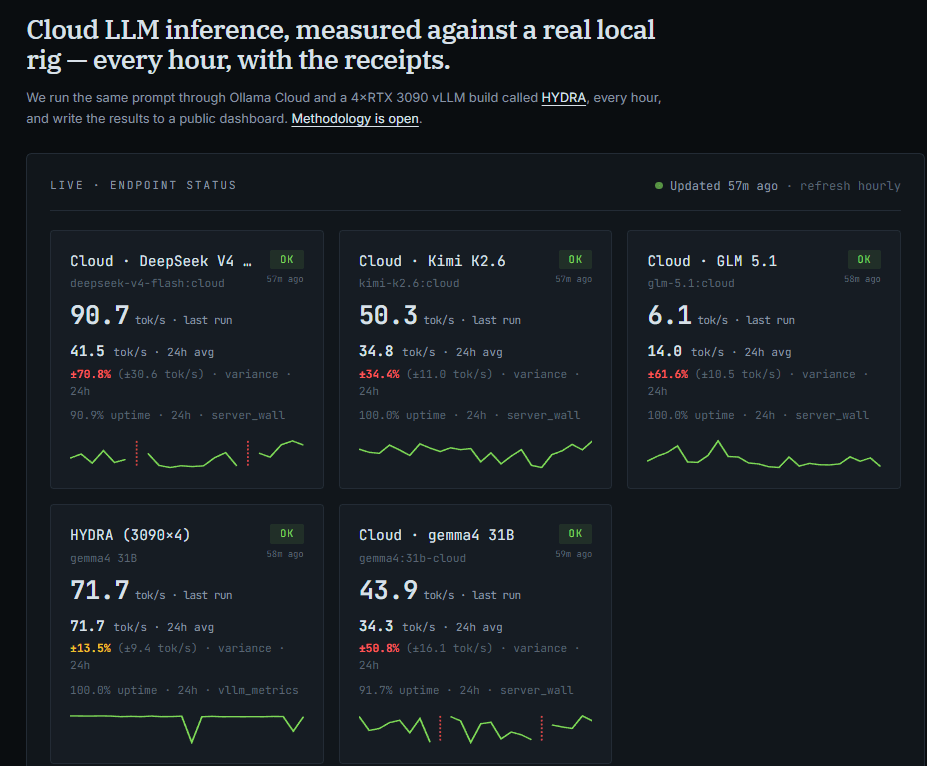
Ollama Watch – Ollwam Cloud 모델 모니터링
요즘 Ollama Cloud 속도가 느려졌다거나 $20/월 서비스 토큰량이 줄었다는 불만이 있습니다. Ollama에서의 공식 발표는 없는 상태인데 Ollama Cloud 속도 문제는 미국 업무 시간대에 특히 느려진다고 합니다. 전에 Ollama에서 GPU 수급이 어려워서 내부 컴퓨팅 파워가 부족해지고 있다는 언급이 있었는데 이와 관련한 것이 아닐까 싶기도 합니다. Ollama Watch는 Ollama Cloud 모델별 응답(?) 성능(TPS)을 보여 주는 모니터링 사이트입니다. 1시간에 한 번씩 동일한 프롬프트에 대한 회신 성능을 모델별로 기록한다고 하는데 24시간 변동을 보면 30~70%까지 모델별 성능 차이가 있는 것을 보면 ollama cloud 서비스가 매우 불안정하다고 볼 수 있겠습니다. Ollama Cloud 모델 선택하실 때 참고하시기 바랍니다.
※ 지난 게시글:
- AI 뉴스 훑어보기 – 2026.6.18
- AI 뉴스 훑어보기 – 2026.6.17
- AI 뉴스 훑어보기 – 2026.6.16
- AI 뉴스 훑어보기 – 2026.6.10
- AI 뉴스 훑어보기 – 2026.6.4
※ 출처: r/LocalLLM, r/openclaw, r/unsloth, r/opencode, r/claude






