
 2023 애니 강추 작품 !")
")




한빛+ 도서 증정 이벤트 놓치지 마십시오. OpenAI에서 4월 22일에 발표한 Workspace Agent, Privacy Filter 소식을 읽어 보십시오. mm find, mm grep, mm cat 이용해서 보다 쉽게 파이프라인 구축하실 수 있습니다.
[이벤트] 한빛+ 독점 콘텐츠 평생 무료 소장 이벤트
무료로 한빛미디어 도서를 받으세요. 오늘은 “비전공자를 위한 클로드 코드” 입니다. 5/17까지 진행한다고 하니 늦지 마시고 좋은 책 많이 받으세요. (‘한빛+’과는 아무런 관련 없습니다.)
ChatGPT – Workspace Agent 소개
개념 요약
- Workspace agents는 ChatGPT의 팀용 공유형 에이전트 기능으로, Codex 기반으로 클라우드에서 동작하며 장기적·복잡한 워크플로우 수행 가능.
- GPTs의 진화형으로, 파일·코드·도구·메모리 등 워크스페이스 자원에 접근해 작업을 계속 수행할 수 있음.
기능 및 활용
- 보고서 작성, 코드 작성/실행, 메시지 응답, CRM 업데이트 등 실제 업무 자동화.
- 스케줄 실행 가능, Slack과 ChatGPT 등에서 동작, 여러 도구와 연동해 컨텍스트 수집 및 액션 수행.
- 메모리와 대화 교정으로 사용하면서 성능 개선 가능.
예시 에이전트 템플릿 / 사용 사례
- Software Reviewer: 소프트웨어 요청 심사·정책 확인·IT 티켓 자동 생성.
- Product Feedback Router: Slack·지원 채널·공개 포럼에서 피드백 수집·우선순위화·주간 액션 생성.
- Weekly Metrics Reporter: 매주 데이터 자동 조회·차트·요약 보고서 작성.
- Lead Outreach Agent: 인바운드 리드 조사·스코어링·맞춤 후속 이메일 및 CRM 업데이트.
- Third-Party Risk Manager: 공급업체 제재·재무·평판 리스크 스크리닝 및 보고서 작성.
- 금융·영업·마케팅 등 템플릿 제공, 사용자 맞춤 설정 가능.
빌드 및 공유
- ChatGPT 사이드바의 Agents에서 워크플로를 설명하면 단계별로 에이전트를 만드는 가이드 제공.
- 팀 내 공유·복제 가능, 사용·수정하면서 표준화된 프로세스화 가능.
통제·거버넌스·안전장치
- 조직이 에이전트에 접근할 수 있는 도구·데이터·행동을 통제 가능.
- 민감한 작업(스프레드시트 편집, 이메일 발송 등)에 대해 승인 요구 설정 가능.
- 관리자용 모니터링·분석(실행 횟수, 사용자 등), 에이전트 일시중지 가능.
- 엔터프라이즈 수준의 가시성·역할 기반 제어, 프롬프트 인젝션 등 외부 공격에 대한 보호 장치 언급.
- Compliance API 및 관리자 콘솔 통합(일부 기능은 향후 제공 예정).
가용성·가격·출시
- 연구 프리뷰로 ChatGPT Business, Enterprise, Edu, Teachers 플랜에서 사용 가능.
- 무료 제공은 2026년 5월 6일까지이며, 이후 크레딧 기반 과금 전환 예정.
※ Workspace Agent: https://openai.com/academy/workspace-agents/
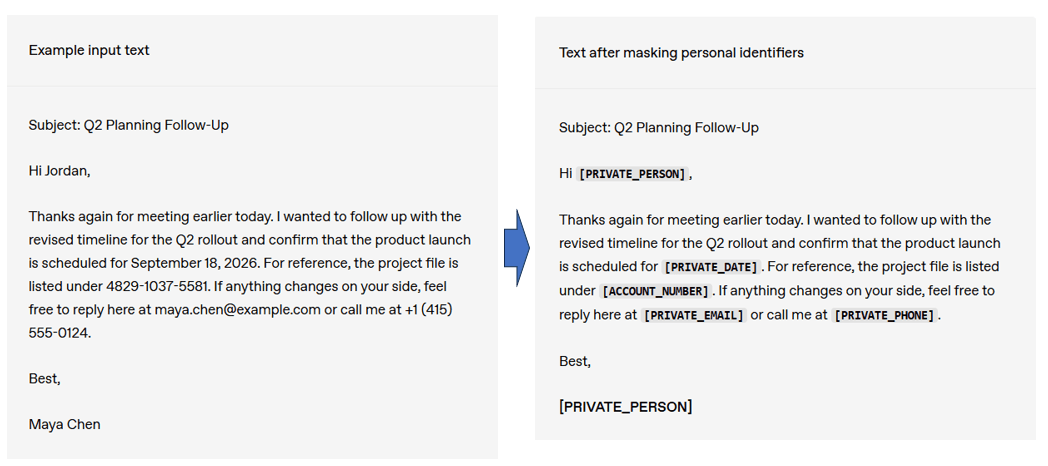
OpenAI가 개인 식별 정보(PII) 검출·마스킹을 위해 공개한 모델인 “Privacy Filter” 공개
목적과 장점
- 텍스트 내 문맥을 고려한 PII 탐지 및 마스킹(단순 정규식보다 문맥 인식에 강함).
- 로컬 실행 가능(데이터를 외부로 전송하지 않고 기기 내에서 처리 가능).
- 대용량 입력(최대 약 128,000 토큰)도 효율적으로 처리.
- 고처리량 프라이버시 파이프라인에 적합.
모델 구조·사양
- 모델 유형: 양방향 토큰 분류기(스팬 디코딩 사용), autoregressive 체크포인트에서 변환.
- 파라미터: 총 1.5B, 활성 파라미터 50M.
- 디코딩: BIOES 태그와 제약된 Viterbi 절차로 일관된 스팬 출력 생성.
- 운영점(정밀도/재현율) 조정 가능.
탐지 카테고리 (8개)
- private_person
- private_address
- private_email
- private_phone
- private_url
- private_date
- account_number
- secret
※ account_number는 신용카드·계좌번호 등 다양한 계정번호를, secret은 비밀번호·API 키 등 비밀값을 포함하도록 설계.
성능
- 표준 벤치마크(PII-Masking-300k)에서 F1 ≈ 96% (정밀도 94.04%, 재현율 98.04%).
- 주석 문제를 보정한 데이터에서는 F1 ≈ 97.43% (정밀도 96.79%, 재현율 98.08%).
- 도메인 적응은 소량의 데이터만으로도 성능이 빠르게 개선됨(예시: F1 54% → 96%).
학습·데이터
- 공개 데이터와 합성 데이터 혼합으로 학습. 주석이 불완전한 공개 데이터는 모델 보조 주석과 검토로 보완.
- 문맥·포맷 다양성을 높이기 위한 합성 예제 포함.
제한점·주의사항
- 익명화 도구나 규정 준수 인증을 대체하지 않음. 고위험 도메인(법률·의료·금융)에서는 인간 리뷰·도메인 특화 검증 필요.
- 언어·스크립트·명명 규칙·도메인 차이에 따라 성능 변동 가능.
- 드물거나 모호한 식별자는 놓치거나 과다 마스킹할 수 있음.
공개·라이선스·문서
- Apache 2.0 라이선스로 공개됨.
- 모델과 문서(아키텍처, 라벨 체계, 디코딩 제어, 사용 사례, 평가 및 한계 설명)가 함께 제공됨.
- 모델은 배포(로컬 실행), 커스터마이즈(미세조정), 상업적 적용을 염두에 둔 공개 배포임.
- 배포 플랫폼으로는 공개 모델 허브와 코드 저장소에 게시되었음(플랫폼명은 언급됨).
예시(본문에 있는 샘플)
원문 이메일 예시에는 사람 이름, 이메일 주소, 전화번호, 날짜, 프로젝트 파일 번호(계정번호형식) 등이 포함되어 있었고, 마스킹 결과는 [PRIVATE_PERSON], [PRIVATE_DATE], [ACCOUNT_NUMBER], [PRIVATE_EMAIL], [PRIVATE_PHONE] 등으로 대체됨.
Intel Arc Pro B70 지원하는 LLM-Scaler vllm-0.14.0-b8.2 발표
Intel 개발한 LLM-Scaler가 최신 Intel AI GPU인 Arc Pro B70을 지원하는 버전을 발표했습니다. Nvidia CUDA, AMD ROCm 에 밀려있는 Intel에서 얼마 전 Intel Arc Pro B70(32GB VRAM)을 $1,000 이하라는 엄청나게 저렴(?)한 가격으로 발표를 했습니다. 이 카드를 지원하는 추론 엔진 LLM-Scaler 버전이 나왔다고 합니다. 있는지도 몰랐네요. 🙁
※ LLM-Scaler https://github.com/intel/llm-scaler
Unsloth/Qwen 3.6-27B 발표
모델 개요
- 이름: unsloth / Qwen3.6-27B-GGUF (Qwen3.6 계열의 오픈 웨이트, GGUF 형태의 양자화 배포)
- 유형: 인과(자연어) 언어 모델 + 비전 인코더(이미지/비디오 입력 지원)
- 라이선스: Apache-2.0
아키텍처·사양(주요 수치)
- 파라미터: 27B
- 레이어 수: 64
- 히든 차원: 5120
- 토큰 임베딩(패딩 포함): 248,320
- 컨텍스트 길이(기본): 262,144 토큰; 확장 가능(최대 약 1,010,000 토큰, YaRN 사용 시)
기능·특징
- Thinking 모드: 기본적으로 모델이 내부 추론(생각)을 먼저 생성한 뒤 최종 응답을 줌(특정 태그/옵션으로 비활성화 가능).
- Preserve thinking: 과거 메시지의 추론(생각) 흔적을 유지해 에이전트 시나리오에서 일관성 및 토큰 절약 향상 가능.
- 에이전틱 코딩(Agentic coding) 지원: 개발자 워크플로우, 레포지토리 수준 추론에 개선점.
- 도구 호출(tool calling) 개선: 중첩 객체 파싱 등의 향상, Qwen-Agent와 통합 권장.
- 멀티토큰 예측(MTP) 및 speculative generation 옵션 제공.
- 멀티모달 입력(이미지/비디오) 예시 및 처리 옵션(프레임 샘플링 등) 포함.
배포·서빙 권장 프레임워크
- 권장: SGLang, vLLM, KTransformers (고성능/생산용), Hugging Face Transformers는 빠른 테스트용.
- 예시 서버 실행 및 파라미터(텐서 병렬, 컨텍스트 길이, 도구 호출 파서, MTP 등) 관련 예제가 포함되어 있음.
장기 컨텍스트(YaRN) 처리
- YaRN(로페 스케일링) 지원 방법 설명: 모델 config 수정 또는 프레임워크별 커맨드라인 오버라이드 제시.
- 권장: 장기 문맥을 자주 쓰면 적절한 scaling factor로 config 조정 권장(짧은 텍스트에서 성능 저하 주의).
생성(샘플링) 권장 설정
- Thinking 모드(일반): temperature=1.0, top_p=0.95, top_k=20 등
- 코드(정밀): temperature=0.6, top_p=0.95, top_k=20 등
- Instruct(비사고/직접응답): temperature=0.7, top_p=0.80, presence_penalty 높음 등
- 출력 길이 권장: 일반적으로 32,768 토큰, 복잡한 벤치마크는 최대 81,920 토큰 권장
양자화·하드웨어 호환성(요약)
- GGUF로 다양한 비트 폭(2비트 ~ 16비트/BF16) 양자화된 버전 제공. (예: 2비트 ~9–12GB 범위, 4비트 ~15–17GB, 8비트 ~28.6GB, BF16 ~53.8GB 등—양자화 방식에 따라 저장·메모리 요구량 상이)
- Unsloth의 Dynamic 2.0 Quants 등 커스텀 양자화 컬렉션 존재.
실무 팁·권장 사항
- 대규모/생산 환경엔 전용 서빙 엔진(vLLM, SGLang 등) 권장.
- 생각 모드 비활성화, preserve_thinking 설정 등은 API 파라미터(채팅 템플릿 옵션 등)로 제어 가능.
- 복잡한 장기 문맥 처리 시 YaRN 설정과 모델 config(rope_parameters) 조정 권장.
- 출력 포맷 표준화를 위한 프롬프트 패턴(예: 수학 문제의 step-by-step 지시, JSON 응답 포맷 등) 권장.
mm – Unix tools (find/cat/grep)

mm – 에이전트를 위한 빠르고 다양한 형식의 컨텍스트 제공 도구입니다.
코딩 에이전트는 텍스트는 잘 읽지만, 디렉터리에 이미지, 비디오 또는 시각적 콘텐츠가 풍부한 PDF 파일이 있는 경우 의미 있는 컨텍스트를 추출하는 데 어려움을 겪습니다. mm은 기존에 사용하던 UNIX 도구(find/cat/grep/wc)를 기반으로 하되, LLM(Learning Language Manager)이 기본적으로 읽을 수 없는 파일 형식까지 지원하도록 설계하여, 간편하고 친숙하게 사용할 수 있도록 했습니다.
mm find, mm cat, mm grep은 기존과 동일한 의미 체계를 유지하면서 이미지, 비디오, 오디오, PDF 파일 등 다양한 형식의 파일에서 작동합니다.
mm grep "invoice #1234" ~/Downloads는 PDF 파일에서 “invoice #1234“를 검색하고 줄 번호가 매겨진 일치 항목을 반환합니다.mm cat photo.jpg는 사진의 캡션을 반환합니다(1초 이내).mm cat ad.mp4는 비디오의 캡션을 반환합니다(5초 이내).
이러한 모든 명령어를 CLI 에이전트의 컨텍스트로 바로 파이프할 수 있습니다.
저희가 특히 신경 썼던 몇 가지 사항은 다음과 같습니다.
- 속도: 핵심 경로에는 Rust 코어 사용
- 로컬 우선, BYO 모델 지원: OpenAI 호환 엔드포인트
(Ollama, vLLM/SGLang, LMStudio 등)와 모든 멀티모달 LLM(Gemma4, Qwen3.5, GLM-4.6V) 사용 - 모든 입력은 파이프라인 방식으로 처리 및 조합 가능: 표준 입력, 구조화된 출력
mm-cli-skills를 통해 모든 에이전트에 통합 가능: Claude 코드, Codex, Gemini CLI, OpenClaw
(추천 글) 프롬프트에서 하네스까지 — AI 에이전틱 패턴 4년의 기록
※ 지난 게시글:
- AI 뉴스 훑어보기 – 2026.7.16
- AI 뉴스 훑어보기 – 2026.7.15
- AI 뉴스 훑어보기 – 2026.7.13
- AI 뉴스 훑어보기 – 2026.7.10
- AI 뉴스 훑어보기 – 2026.7.9
※ 출처: r/LocalLLM, r/openclaw, r/unsloth, r/opencode, r/claude






