
 2023 애니 강추 작품 !")
")




Pixal3D, Krea 3의 오픈 소스 버전 발표, 4B~36B 소형 모델을 사용한 SmallCode 안정화 버전 출시, Tencent Hy-MT2 다국어 번역 모델 출시, Ant 그룹의 Ring-2.6-1T 출시 소식이 있습니다. 이 외에도 Bluetooth Smart LAMP를 Codex 상태 신호기로 만든 재미난 프로젝트 소식도 있습니다.
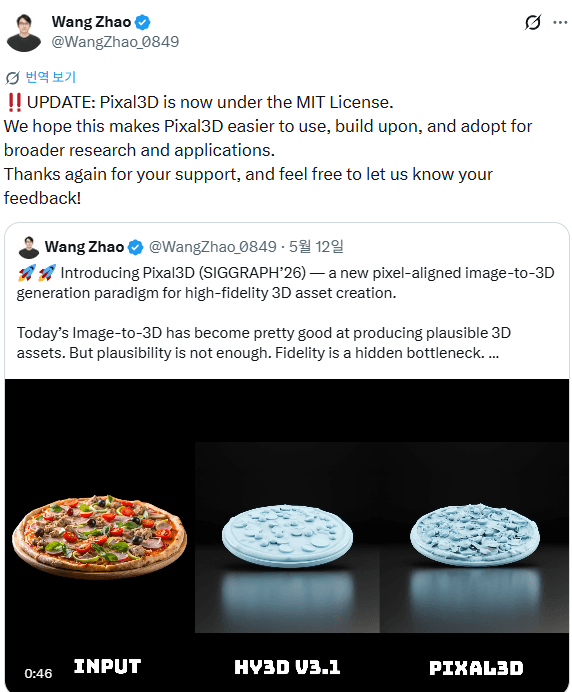
Pixal3D, 오픈소스 MIT 라이선스로 전환
Pixal3D는 생성된 3D 형상을 입력 이미지의 픽셀에 직접 정렬하는 혁신적인 3D 생성 패러다임으로, 기존의 특징점 주입 방식과는 차별화됩니다. 쉽게 말해서 2D 이미지를 3D 이미지 에셋으로 변경해 줍니다.
5/21 X를 통해 발표한 내용입니다. TencentARC에서 개발한 고품질 3D 에셋 생성 모델인 Pixal3D가 공식적으로 라이선스를 MIT로 변경하여 상업적 사용이 제한 없이 가능해졌습니다. 이번 변경 사항은 GitHub에서 확인되었으며, 기존의 법적 제약 없이 오픈 소스 워크플로우에 통합할 수 있게 되었습니다. 이번 라이선스 변경으로 EU 내 전문 및 상업적 사용에 대한 중요한 법적 장벽이 제거되어 소프트웨어 엔지니어링 및 AI 워크플로우에 직접적인 영향을 미칩니다. 개발자들은 이제 제한적인 저작권 조건에 대한 걱정 없이 Pixal3D를 독점 소프트웨어에 통합할 수 있습니다. Pixal3D는 역투영 방식을 사용하여 픽셀 특징을 3D로 명시적으로 표현함으로써, 상세한 형상과 PBR 텍스처를 통해 거의 재구성 수준의 높은 품질을 구현합니다. 또한, 여러 참조 이미지를 사용하여 3D 모델을 생성할 수 있는 멀티뷰 모드의 출시도 기대를 모으고 있습니다.
Krea 2, 오픈 소스로 변경
Krea 팀은 차세대 이미지 생성 모델인 Krea 2의 오픈 소스 버전을 공개한다고 발표했습니다. 다만, 현재 유료 서비스에서 제공되는 버전과 완전히 동일한 버전은 아닐 수 있습니다. 이번 발표로 커뮤니티의 진입 장벽이 크게 낮아져 개발자들이 라이선스 제한 없이 Krea 2의 스타일 전송 아키텍처를 기반으로 새로운 기능을 개발할 수 있게 되었으며, 이는 AI 기반 예술 도구 분야의 혁신을 가속화할 것으로 기대됩니다. 전체 아키텍처 세부 정보는 아직 완전히 공개되지 않았지만, Krea 2는 단순히 빠른 응답 속도보다는 미적 감각과 스타일 제어에 중점을 둔 것으로 알려져 있어 공식 출시 전 성능 저하 가능성에 대한 우려가 제기되고 있습니다.
Krea 2는 기존의 확산(Diffusion) 모델에서 벗어나 처음부터 새롭게 구축된 기반(Foundation) 모델로 전환한 것으로, Stable Diffusion과 유사한 스타일 전송 기능을 강조하면서도 시각적 취향에 초점을 맞추고 있습니다.
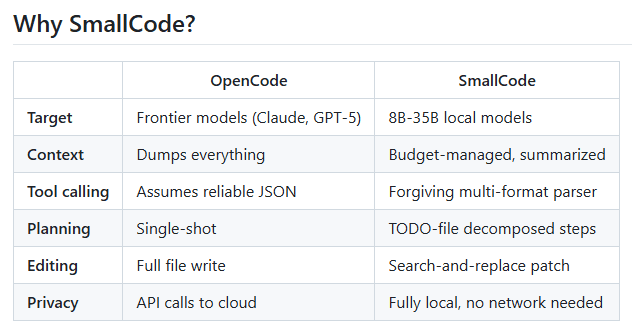
SmallCode 안정화 버전 출시
기존 SmallCode 버전의 90개 이상 버그를 수정하고 TUI/명령줄 충돌 문제를 해결한 후, 4B~36B 파라미터 모델을 위한 에이전트 코딩 도구인 ‘SmallCode’를 안정화했습니다. 이번 릴리스는 기존에 불안정한 도구로 어려움을 겪었던 로컬 개발자들의 중요한 문제점을 해결하고, 프론티어 모델에 의존하는 에이전트에 대한 안정적인 오픈 소스 대안을 제공합니다. SmallCode는 4B(40억) 활성 파라미터만을 사용하여 SWE-bench에서 87%의 점수를 획득했으며, 더 적은 반복 횟수에도 불구하고 소규모 모델에서 OpenCode와 같은 경쟁 도구를 크게 능가합니다.
OpenAI Codex에 앱샷, 목표 모드 및 원격 제어 기능 추가
macOS용 Codex 앱이 이제 Appshots 기능을 지원하여 사용자가 Command 키를 두 번 누르는 것만으로 앱 창의 스크린샷과 텍스트를 전송할 수 있게 되었습니다. 또한 장기적인 자율 작업을 위한 Goal 모드가 정식 출시되었습니다. 더불어 원격 컴퓨터 사용 기능이 추가되어 Mac이 잠긴 후에도 Codex가 데스크톱 애플리케이션을 실행할 수 있게 되었습니다. 이번 업데이트는 데스크톱 환경에서 자율 AI 에이전트를 사용하는 방향으로의 중요한 전환을 의미하며, 수동 컨텍스트 전환을 줄이고 이전에는 실험적이었던 지속적이고 장기적인 워크플로우를 가능하게 합니다. 앱 간 컨텍스트 및 원격 실행을 위한 강력한 도구를 제공함으로써 에이전트 개발의 주요 문제점을 해결하지만, 플랫폼 호환성은 여전히 커뮤니티의 과제로 남아 있습니다. Appshots는 특정 키보드 단축키를 사용하여 가장 앞에 있는 앱 창의 스크린샷과 사용 가능한 텍스트를 캡처하며, Goal 모드는 이제 Codex 앱, IDE 확장 프로그램 및 CLI 전반에서 지속적인 자율 작업을 위해 사용할 수 있습니다. 원격 컴퓨터 사용에는 잠금 화면 작업 중 보안을 보장하기 위해 단기 인증 및 화면 가림과 같은 보호 조치가 포함되어 있습니다.
텐센트, Hy-MT2 다국어 번역 모델 출시
텐센트는 1.8B, 7B, 30B-A3B 크기의 다국어 번역 모델인 Hy-MT2 제품군을 출시했습니다. 이 모델들은 온디바이스 배포를 위해 AngelSlim 1.25비트 양자화 기술을 적용했습니다. 33개 언어 간 번역을 지원하며, 빠른 사고(fast-thinking) 모드에서 DeepSeek-V4-Pro와 같은 모델들을 능가한다고 합니다. 이번 출시는 고성능, 저지연 번역 솔루션을 제공하여 상용 API를 대체할 수 있다는 점에서 언어 번역(LLM) 사용자 및 연구자들에게 중요한 의미를 갖습니다. 초고속 양자화 기술 덕분에 온디바이스에서 효율적인 추론이 가능해져 기존 모델의 저장 용량 및 속도 제한 문제를 해결했습니다. 1.8B 모델은 AngelSlim 양자화를 통해 저장 용량을 440MB로 줄이면서 추론 속도를 1.5배 향상시켰고, 30B-A3B 모델은 MoE(Mixture of Experts) 아키텍처를 사용합니다. 텐센트는 또한 손쉬운 통합을 위해 IFMTBench 벤치마크와 Translator Skill을 오픈소스로 공개했습니다.

Ring-2.6-1T, 에이전트 성능 면에서 최첨단(SOTA) 수준
Ant Group은 에이전트 워크플로우에 최적화된 1T 추론 모델인 Ring-2.6-1T를 출시했습니다.
※ 주요 특징: MIT 라이선스, 128K~256K 컨텍스트, 비동기 RL + IcePop 학습, 그리고 두 가지 추론 난이도(높음 및 매우 높음)를 제공합니다.

시니어 엔지니어가 공유한 Claude Code 이용한 모바일 ‘바이브 코딩’ 워크플로우
10년 경력의 소프트웨어 엔지니어가 Claude Code를 사용하여 모바일 사이드 프로젝트를 구축하는 성공적인 워크플로를 공유하며, 실행 전에 생성된 계획을 철저히 이해하는 것이 얼마나 중요한지 강조합니다. 이 워크플로는 모든 코드 줄을 읽는 기존의 사고방식에 도전하여, 높은 수준의 이해와 반복적인 계획 수립을 우선시합니다. 이를 통해 인지 부하를 줄이면서도 코드 품질을 유지하는 확장 가능한 AI 지원 개발 방식을 제시합니다. 엔지니어는 큰 계획을 작고 이해하기 쉬운 단위로 나누고, ‘Claude에게 무엇을 변경해야 하는지 알려줘’와 같은 구체적인 기술을 사용하여 불분명한 부분을 명확히 함으로써 에이전트 범위를 관리 가능한 수준으로 유지하고 디버깅 과정에서 발생하는 혼란을 방지할 것을 조언합니다.
인공지능의 비판적 사고를 촉진하는 프롬프트 프레임워크
새로운 프롬프트 엔지니어링 기법은 사용자가 AI에게 직접적인 답변을 제공하기 전에 먼저 숨겨진 가정, 필요한 정보, 그리고 흔히 발생하는 오류를 파악하도록 요청하도록 안내합니다. 이 프레임워크는 상호작용 방식을 즉각적인 응답에서 명확화 및 비판적 분석을 포함하는 구조화된 프로세스로 전환합니다. 이 기법은 논리 학습 모델(LLM)을 단순한 답변 생성기에서 사용자의 추론 오류를 드러내는 도구로 변화시켜 비즈니스 전략 및 채용과 같은 영역에서 의사결정의 질을 향상시킨다는 점에서 중요합니다. 이는 논리 학습 모델이 잘못된 전제를 의심 없이 받아들이는 일반적인 문제를 해결합니다. 이 프레임워크는 AI가 사용자의 질문에 최종적으로 답변하기 전에 명시되지 않은 가정, 답변을 바꿀 수 있는 정보, 그리고 흔히 발생하는 오류라는 세 가지 항목을 출력하도록 요구합니다. 사용자들은 이 세 번째 항목에서 사용자가 인지하지 못했던 숨겨진 편견이나 논리적 오류를 발견하는 경우가 많다고 지적했습니다.
Don't answer my question yet. First do this: 1. Tell me what assumptions I'm making that I haven't stated out loud 2. Tell me what information would significantly change your answer if you had it 3. Tell me the most common mistake people make when asking you this type of question Then ask me the one question that would make your answer actually useful for my specific situation rather than anyone who might ask this Only after I answer — give me the output My question: [paste anything here]
블루투스 램프를 Codex 상태 표시기로 만들기
Codex Hook을 사용하여 Bluetooth Low Energy(BLE) 램프를 제어하는 Python 스크립트를 실행하는 오픈 소스 프로젝트를 개발했습니다. 이 프로젝트는 모델의 활동, 입력 요구 사항 또는 유휴 상태를 나타내기 위해 파란색, 분홍색 또는 따뜻한 흰색 빛을 표시합니다. 이 통합 사례는 복잡한 네트워크 구성이나 Wi-Fi 의존성 없이도 하드웨어 피드백 루프를 통해 AI 에이전트를 확장하고 시스템 부하에 대한 사용자 인식을 향상시키는 방법을 보여줍니다. 이 솔루션은 Codex SDK를 활용하여 Hook을 통해 스크립트를 실행하고, 스크립트는 bt-lamp 라이브러리를 사용하여 램프와 통신합니다. Linux 시스템에서 BLE 스택에 접근하려면 sudo 권한이 필요합니다.
ik_llama.cpp를 사용하여 Qwen3.6 35B에서 110 tok/s 얻음
ik_llama.cpp를 사용하여 12GB VRAM 환경에서 Qwen3.6-35B 모델에 대해 초당 110개의 토큰을 처리하는 데 성공했습니다. 이는 최근 llama.cpp의 MTP 변경으로 인해 발생했던 성능 저하를 되돌린 결과입니다. 이 벤치마크는 RTX 4070 Super 12GB 그래픽 카드와 Ryzen 7 9700X CPU 조합에서 수행되었습니다. 이 성과는 VRAM 용량이 제한적인 일반 소비자용 하드웨어에서 대규모 35B 파라미터 모델에 대한 고성능 추론 기능을 복원했다는 점에서 매우 중요합니다. 이는 표준 llama.cpp 구현에서 최근 발생한 성능 저하 문제를 해결한 것입니다. 또한, 로컬 LLM 생태계에서 효율성을 유지하는 데 있어 ik_llama.cpp와 같은 최적화 포크의 중요성을 강조합니다. 해당 사용자는 IQ4_XS 압축을 적용한 Qwen3.6-35B-A3B 양자화 형식을 사용하여 초당 110개의 토큰을 처리했으며, 이는 표준 llama.cpp MTP 구현에서 관찰된 약 89개의 토큰 처리량보다 훨씬 뛰어난 성능입니다. 결과에 따르면 ik_llama.cpp는 현재 llama.cpp 버전보다 수락률 및 CPU 오프로딩을 더 효율적으로 처리하는 것으로 나타났습니다.
시험 장비 사양:
OS: CachyOS with Plasma (X11) - HIGHLY recommended GPU: RTX 4070 Super 12GB CPU: AMD Ryzen 7 9700X RAM: 48GB DDR5-6000 EXPO I
기존 llama.cpp 성능 시험 결과:
❯ ./mtp-bench.py
code_python pred= 192 draft= 122 acc= 118 rate=0.967 tok/s=79.8
code_cpp pred= 192 draft= 117 acc= 110 rate=0.940 tok/s=89.1
explain_concept pred= 192 draft= 124 acc= 113 rate=0.911 tok/s=88.0
summarize pred= 192 draft= 139 acc= 127 rate=0.914 tok/s=95.0
qa_factual pred= 192 draft= 133 acc= 128 rate=0.962 tok/s=97.0
translation pred= 192 draft= 125 acc= 117 rate=0.936 tok/s=91.6
creative_short pred= 192 draft= 109 acc= 99 rate=0.908 tok/s=82.1
stepwise_math pred= 192 draft= 130 acc= 125 rate=0.962 tok/s=97.0
long_code_review pred= 192 draft= 121 acc= 115 rate=0.950 tok/s=88.2
Aggregate: {
"n_requests": 9,
"total_predicted": 1728,
"total_draft": 1120,
"total_draft_accepted": 1052,
"aggregate_accept_rate": 0.9393,
"wall_s_total": 21.86
}
ik_llamap.cpp 성능 시험 결과:
❯ ./mtp-bench.py
code_python pred= 192 draft= 135 acc= 122 rate=0.904 tok/s=105.1
code_cpp pred= 192 draft= 136 acc= 120 rate=0.882 tok/s=110.3
explain_concept pred= 192 draft= 133 acc= 116 rate=0.872 tok/s=109.0
summarize pred= 56 draft= 38 acc= 37 rate=0.974 tok/s=122.3
qa_factual pred= 192 draft= 141 acc= 127 rate=0.901 tok/s=116.0
translation pred= 192 draft= 143 acc= 113 rate=0.790 tok/s=104.1
creative_short pred= 192 draft= 133 acc= 118 rate=0.887 tok/s=109.4
stepwise_math pred= 192 draft= 140 acc= 125 rate=0.893 tok/s=114.6
long_code_review pred= 192 draft= 128 acc= 108 rate=0.844 tok/s=101.4
Aggregate: {
"n_requests": 9,
"total_predicted": 1592,
"total_draft": 1127,
"total_draft_accepted": 986,
"aggregate_accept_rate": 0.8749,
"wall_s_total": 16.64
}(참고) llama.cpp 실행 파라메터는 원 출처에서 확인하실 수 있습니다.
Qwen3.6-27B 및 ROCm을 사용한 고성능 로컬 LLM 설정
ROCm 백엔드와 MTP 투기적 디코딩(speculative decoding)을 사용하는 Qwen3.6-27B 모델을 듀얼 RX 9070 XT GPU에서 활용하여 고성능 로컬 LLM(Long-Term Memory) 환경을 구축했습니다. 이 게시물에는 특정 구성 파일과 llama.cpp 관리자 ggerganov가 제공한 유용한 팁(성능 향상을 위해 –spec-default 플래그를 추가하는 방법)이 포함되어 있습니다. 이 구성은 특히 AMD GPU를 사용하고 클라우드 종속성 없이 추론 속도를 최적화하려는 로컬 LLM 개발자에게 즉각적인 실질적인 이점을 제공합니다. 관리자의 권장 사항이 포함됨으로써 기술적 접근 방식의 타당성이 입증되고 투기적 디코딩 기법의 커뮤니티 도입이 촉진됩니다. 이 환경은 Q5_K_XL로 양자화된 Qwen3.6-27B-MTP-GGUF 모델을 사용하며, 전력 제한이 약 235W인 듀얼 PCIe 5.0 GPU에서 실행되어 MTP 투기적 디코딩을 통해 높은 초안 승인률을 달성합니다. 주요 매개변수에는 컨텍스트 크기 131,072 토큰과 ctxcp 설정을 통해 활성화된 플래시 어텐션이 포함됩니다.
Qwen3.6-35B-A3B의 로컬 에이전트 워크플로우에 자연어 제어 기능 제공
Qwen3.6-35B-A3B를 Pi Agent 프레임워크와 성공적으로 통합하여 DevOps 작업, PDF 변환, Docling 및 Playwright와 같은 도구를 사용한 자동화 테스트를 위한 실행 가능한 스킬을 생성했습니다. 이 설정을 통해 사용자는 기존의 CLI 인터페이스 대신 자연어 명령을 통해 운영 체제 및 소프트웨어 환경을 제어할 수 있습니다. 이는 LLM(로컬 라이프마커)을 단순히 텍스트 생성기로 사용하는 것에서 벗어나 복잡한 소프트웨어 도구를 조율하는 추론 엔진으로 활용하는 실질적인 변화를 보여주며, 프로그래밍 경험이 없는 사용자도 기술적인 작업을 자동화할 수 있도록 진입 장벽을 크게 낮춥니다. 또한 클라우드 API나 외부 서비스에 의존하지 않고 실제 작업을 수행할 수 있는 로컬 AI 에이전트의 성장 추세를 보여줍니다. 이 워크플로는 Codex가 오류 처리를 포함한 상세한 스킬 문서를 생성하는 2단계 프로세스와, Qwen3.6이 MS-02 및 RTX 4000 GPU와 같은 로컬 하드웨어를 사용하여 실제 작업을 실행하는 2단계 프로세스로 구성됩니다. 이제 사용자는 라이브러리 설치 또는 랜딩 페이지 생성과 같은 특정 소프트웨어 작업을 대화형 프롬프트를 통해 완전히 위임할 수 있습니다.
※ 지난 게시글:
- AI 뉴스 훑어보기 – 2026.6.24
- AI 뉴스 훑어보기 – 2026.6.19
- AI 뉴스 훑어보기 – 2026.6.18
- AI 뉴스 훑어보기 – 2026.6.17
- AI 뉴스 훑어보기 – 2026.6.16
※ 출처: r/LocalLLM, r/openclaw, r/unsloth, r/opencode, r/claude
 dcgm-exporter 구성")



